看完了一波分布式深度学习原理,并尝试使用pytorch实现本地两台gpu服务器(各4张卡)之间的通信,结果屡试屡败,太有挫败感,不得已弃之使用人人称道的Horovod。也是在这个时候比较系统地学习了一遍docker,并使用docker成功搭建好了基于Horovod的分布式深度学习环境。下面首先介绍分布式深度学习多机训练机制,后再介绍如何使用Horovod搭建多机训练平台。
分布式深度学习
Background
模型训练时间的长短主要取决于数据集的大小、模型的复杂度(模型的存储和计算量)和硬件资源的利用。而数据集的大小、模型的复杂度固定的情况下,如何充分利用集群/硬件资源来加速模型的训练,这就是分布式深度学习所要研究的内容。
模型复杂度的提升
无论是CV、NLP还是其它涉及到深度学习的领域,往往是模型的复杂度越高,模型的效果越好。所以对于某些偏向于追求效果的研究和应用,现阶段的模型复杂度都相当高,比如GPT-2的1.5 billion的参数。
数据集的增大
BIG DATA时代,很多任务中的数据集往往都是特别大,甚至愈来愈大。比如推荐领域,大公司每天的日志量可能都是T级别及以上。
组成模块
当前的分布式深度学习主要包含如下模块
- 数据与模型划分:模型并行vs数据并行
- 单机优化:优化算法(略)
- 通信机制:网络拓扑(ParameterServer vs Allreduce), 通信步调(同步更新vs异步更新)
- 模型聚合:对单机优化的模型参数/梯度进行汇总,更新新的参数(略)
模型并行vs数据并行
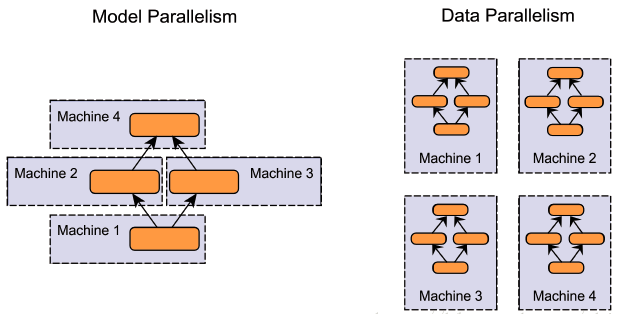
当模型过大无法在单机上存储时,会采用模型并行将模型分割到不通机器上,但多数情况下,一块常规显卡还是能承受住模型的存储开销的,目前训练数据量过大导致的模型训练速度慢才是分布式机器学习领域的主要矛盾。所以大多数情况下还是使用数据并行的方式,每台机器上平均分配一个batch的数据量。
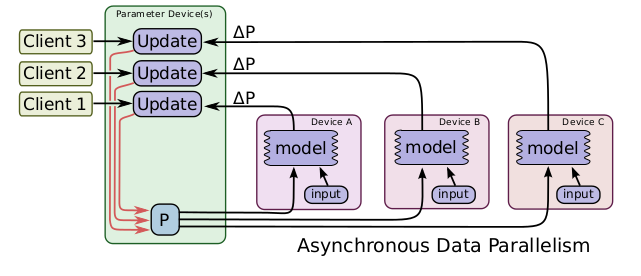
同步更新vs异步更新
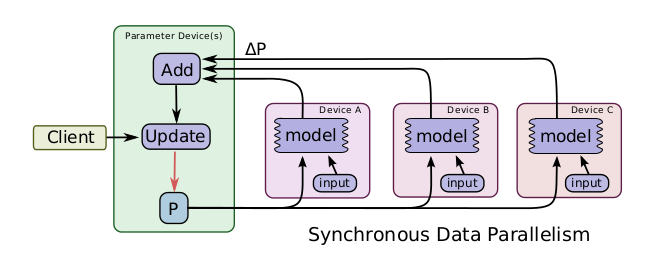
同步更新符合梯度下降的规则,但是更新的速度取决于运算最慢的那台机器。
异步更新虽然不用等,但是会出现梯度延时的问题。如何设计高效的异步更新算法,这也是目前研究的一个热点。
Parameter Server vs Ring Allreduce
在分布式深度学习中,目前主流的通信拓扑结构是PS和Ring Allreduce。拿PS来说,至少经历了三次版本的迭代,这里不打算展开,主要介绍这两种结构的基本思想。
首先看到一个简化的PS的结构:
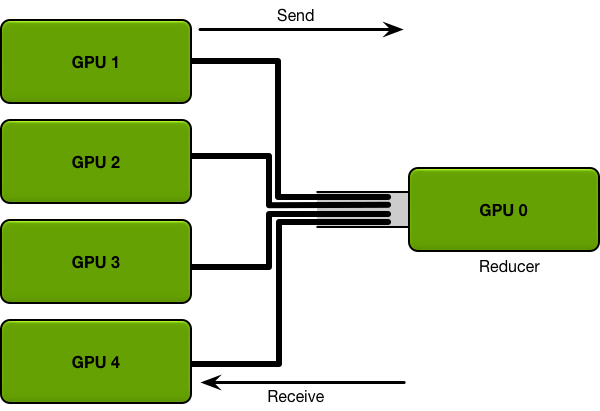
图中GPU 0是server node,其余为worker node。
对于数据并行的同步更新训练过程,所有GPU上开始都存有模型的副本,每一轮迭代所有的worker需要将各自backward得到的参数梯度传递给server来做平均、更新,server更新好参数后再将其复制给所有的worker。
两次传递过程的通信量分别是模型参数及其梯度。从上图可以明显看到,PS的瓶颈出现在server与其余worker之间的通信,在每一轮的迭代中,send和receive的一方总是单个GPU,如此大的通信量都是要和单个GPU打交道,而单个GPU的带宽是很有限的,随着worker数目增加,通信的开销将会越大。举例而言,假设需要训练的模型有300w参数,每个参数是4bytes,那么参数的memory就大约1.2G,最后再假设带宽是1G/s。那么当PS中只有两个node时,每次迭代大概需要1.2s。当PS中有9个worker一个server时,这个开销就至少是10.8s。也即说明随着worker的增加,通信的开销呈线性增长。
为了解决这个问题,百度研究院将HPC中的技术引入了进来,也就是Ring Allreduce。
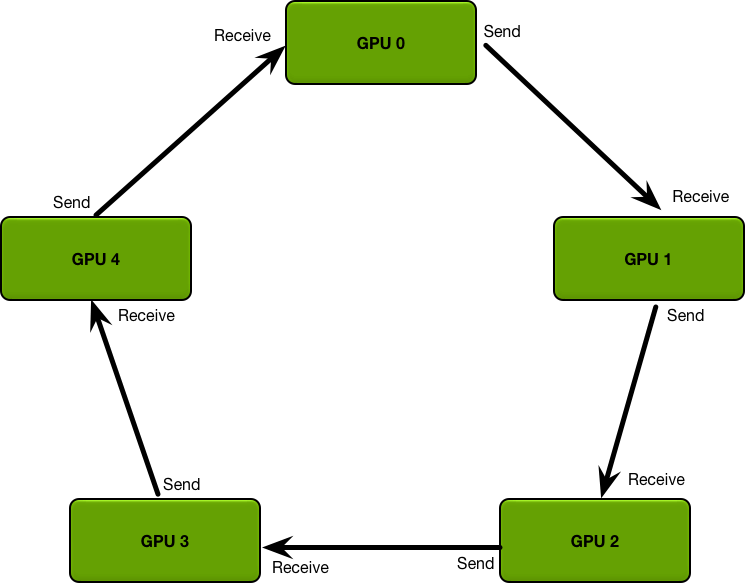
Ring Allreduce中每一个结点都有一个左结点和右结点,并且每一个结点只能从左节点recv,向右结点send。
Ring Allreduce包含两个步骤:先Scatter-Reduce后Allgather,最终目的是在每个结点上都得到参数梯度的平均。
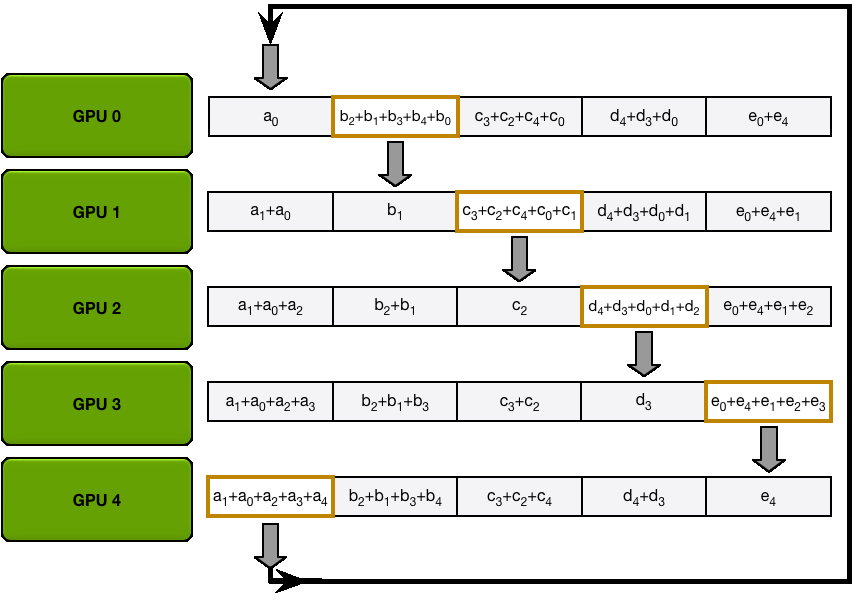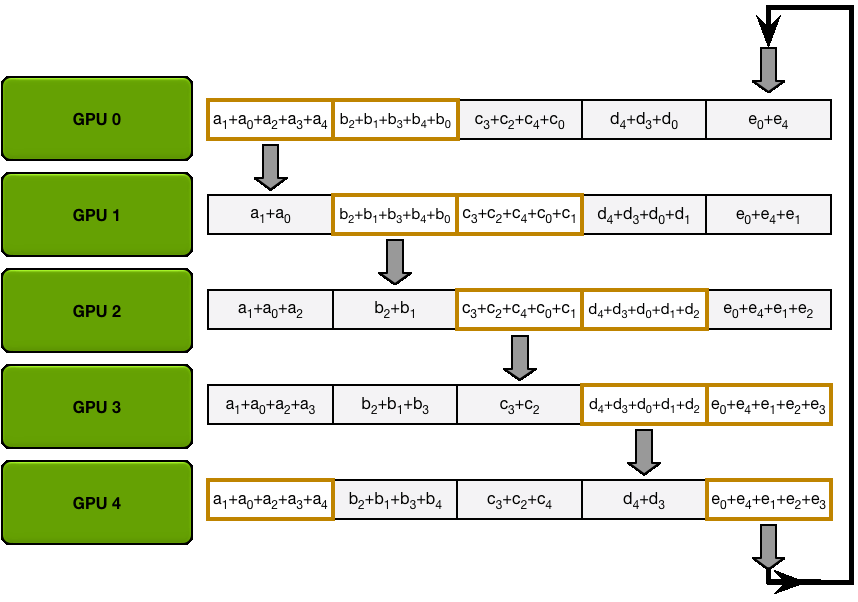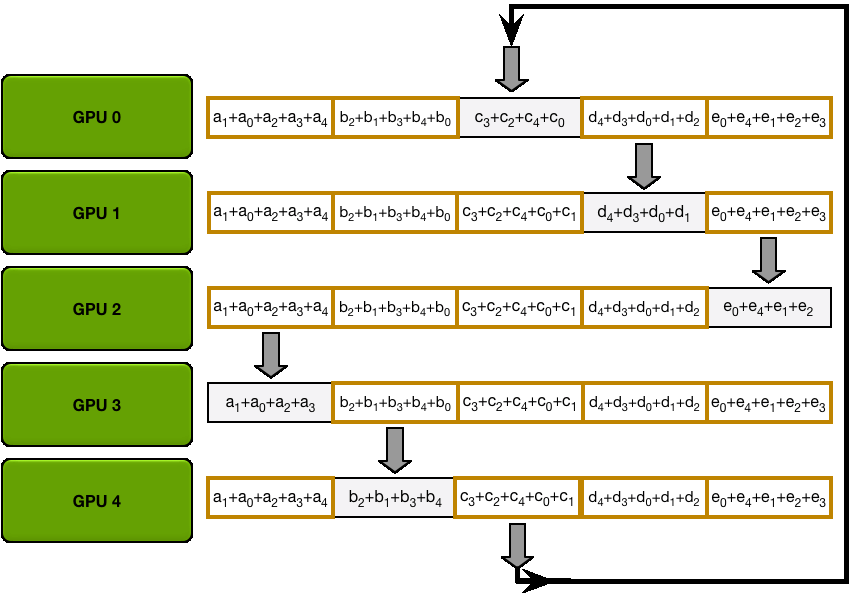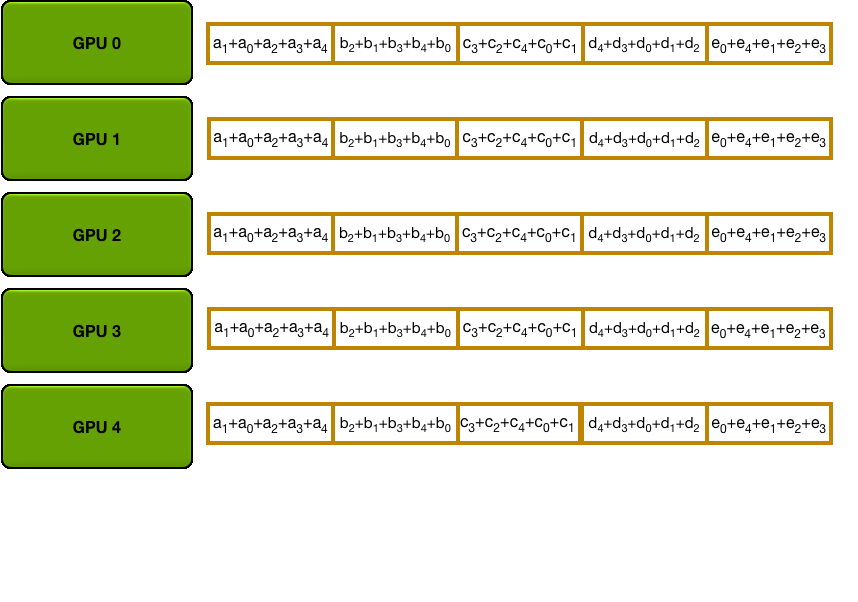
Scatter Reduce 首先在每个结点上将模型参数梯度划分成N个一致的chunks,其中N为Ring上GPU的个数。这样所有结点上模型的参数梯度组合形成一个方阵。同理,每个chunk都相应有自己的右chunk和左chunk,模型参数梯度划分成N个chunk会形成N个chunk ring。
然后从参数梯度方阵对角线上的chunk开始,每个chunk向其右chunk send一份自己的备份,同时右chunk需要recv这个备份并加和。之后经过N-1次迭代,矩阵的右-1对角线chunk和左下角chunk会得到各自所在的chunk ring上所有chunk之和。

All Gather 在Scatter Reduce的基础上,每个GPU上都有一个chunk是其所在chunk ring上的参数梯度之和。所以只需要将这份chunk在其所在的ring上传播N-1次,那么每个GPU上就得到了所有结点上参数梯度之和,这也是All Gather所做的工作。之后各结点对参数梯度求平均即得到整个batch的平均梯度。
Horovod
Horovod是一款分布式训练框架,可用于各大深度学习框架如TF、Pytorch、Keras和MXNet。虽然每一个深度学习框架本身也实现了各自的分布式训练功能,但实作中发现效果并不理想。如下是tensorflow提供的分布式训练效果:
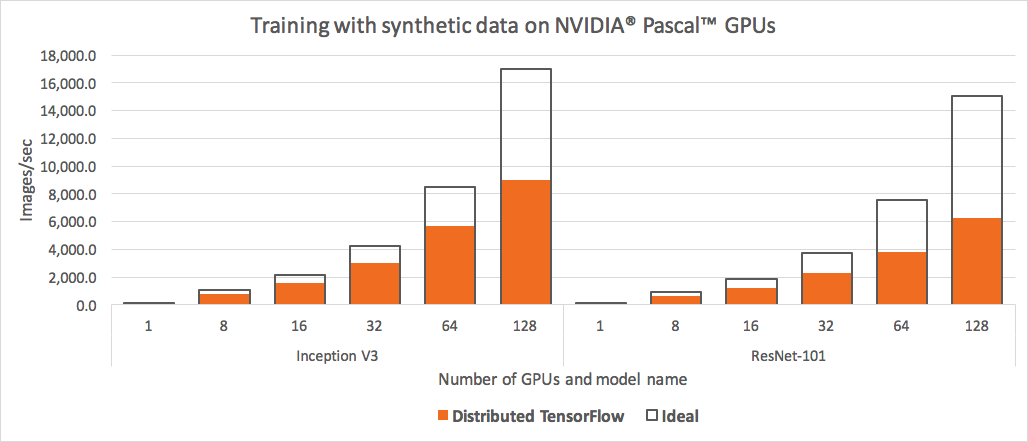
可以很明显看到,tensorflow的加速比随着gpu的增加严重下滑,128卡的情况下居然较Ideal损耗了一半的性能。
horovod就是针对这一问题才出现的,如下是horovod与tensorflow的对比:
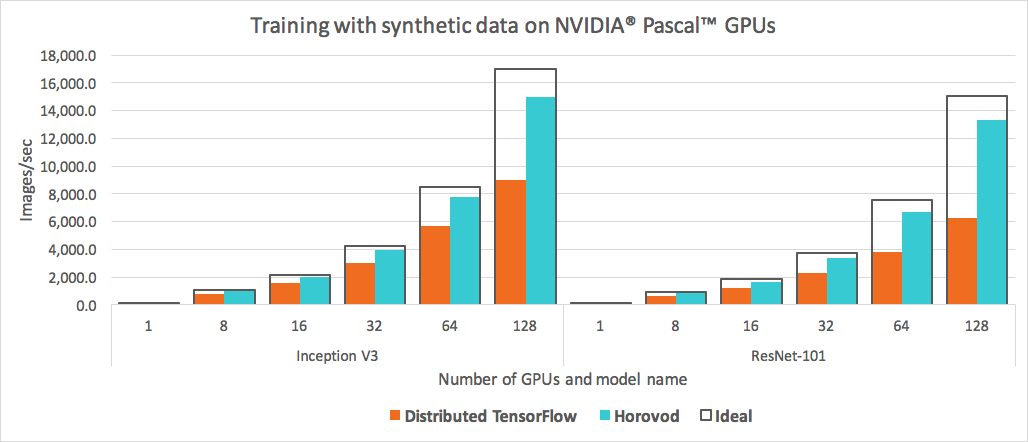
可以看到horovod相较于Ideal性能损耗较小,想必这也是horovod在市面上留有一席之地的根本原因。
Horovod 配置与使用
本文是基于docker环境的horovod配置,需要的主要原材料有:
- docker
- nvidia-docker
docker&nvidia-docker安装
docker
1 | curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - |
nvidia-docker
1 | curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \ |
安装curl
1 | sudo apt-get install curl |
需要注意,可能会出现如下错误:
1 | curl: symbol lookup error: /opt/anaconda3/bin/../lib/libcurl.so.4: undefined symbol: sslv2_client_method |
这是因为anaconda也带了openssl和curl,并且anaconda在环境变量里,所以使用curl的时候会用到anaconda中的curl,笔者在实验中发现这里的curl和openssl有问题,出现了上方的错误。我所采取的解决办法是将anaconda中的openssl和curl改名,然后重装openssl和curl即可。
Horovod in Docker
为了简化GPU机器上的安装过程,Horovod项目发布了Dockerfile,方便我们使用docker来快速配置环境。该容器在/examples目录中包含了Horovod的使用示例。用户也可以在DockerHub中直接下载预先构建好的容器。
Building
在building之前,你可以根据需求对Dockerfile进行修改,比如不同的CUDA、TensorFlow和python版本,也可以在安装的命令中指定源,解决下载慢的问题。
1 | $ mkdir horovod-docker-gpu |
Running on a single machine
镜像构建好之后,使用 nvidia-docker 来启用容器。
1 | $ nvidia-docker run -it horovod:latest |
如果不是以privileged模式运行容器,可能会出现如下问题
1 | [a8c9914754d2:00040] Read -1, expected 131072, errno = 1 |
可以无视之。
Running on a multiple machines
想要在多机上进行训练,最关键的问题是多机之间的通信。下面采用SSH来进行多机之间的免密通信。
首先,我们通过共享文件的方式,使每台机器下的/mnt/share/ssh与容器中的/root/.ssh进行绑定,并且在/mnt/share/ssh中,配置好id_rsa和authorized_keys 对来允许免密登录。
Primary worker:
1 | host1$ nvidia-docker run -it --privileged --network=host -v /mnt/share/ssh:/root/.ssh horovod:latest |
Secondary workers:
1 | host2$ nvidia-docker run -it --network=host -v /mnt/share/ssh:/root/.ssh horovod:latest \ |
1 | host3$ nvidia-docker run -it --network=host -v /mnt/share/ssh:/root/.ssh horovod:latest \ |
1 | host4$ nvidia-docker run -it --network=host -v /mnt/share/ssh:/root/.ssh horovod:latest \ |
以下是笔者成功在两台机器上运行成功的效果图:
1 | mpirun --allow-run-as-root --tag-output -np 6 -H w2:4,w1:2 -bind-to none -map-by slot -mca pml ob1 -mca btl ^openib -mca plm_rsh_args "-p 12345" -mca btl_tcp_if_include ppp0 -x NCCL_SOCKET_IFNAME=ppp0 -x CUDNN_VERSION -x LS_COLORS -x LD_LIBRARY_PATH -x MXNET_VERSION -x HOSTNAME -x NVIDIA_VISIBLE_DEVICES -x NCCL_VERSION -x PWD -x HOME -x TENSORFLOW_VERSION -x PYTORCH_VERSION -x LIBRARY_PATH -x TORCHVISION_VERSION -x TERM -x CUDA_PKG_VERSION -x CUDA_VERSION -x NVIDIA_DRIVER_CAPABILITIES -x PYTHON_VERSION -x SHLVL -x NVIDIA_REQUIRE_CUDA -x PATH -x _ -x HOROVOD_STALL_CHECK_TIME_SECONDS -x HOROVOD_STALL_SHUTDOWN_TIME_SECONDS -x HOROVOD_NUM_NCCL_STREAMS -x HOROVOD_MLSL_BGT_AFFINITY python keras_mnist_advanced.py |
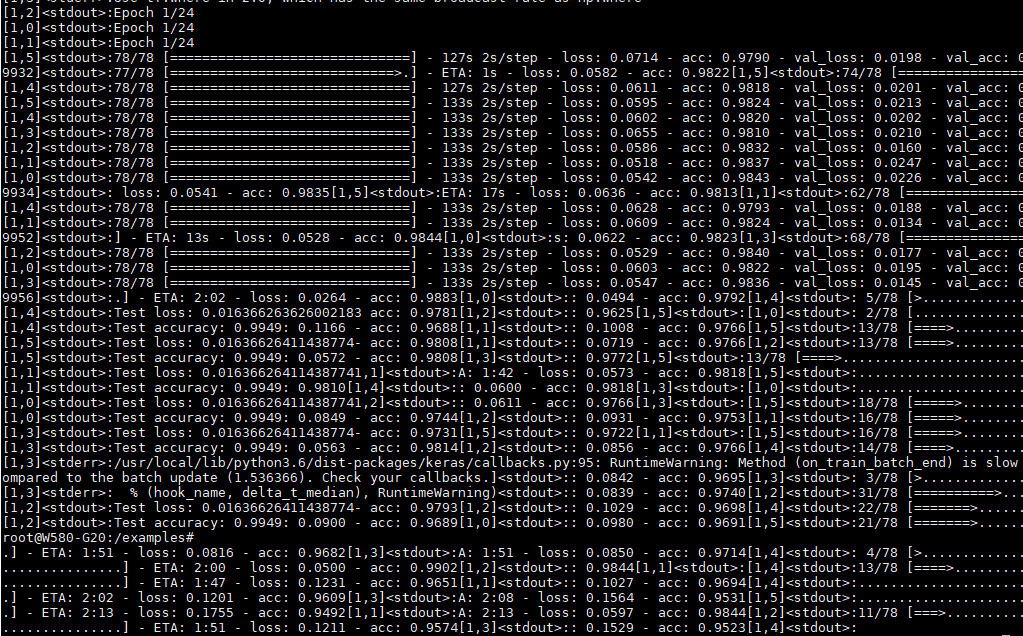
由于笔者资源有限,只有两台机器,而且机器之间的网络传输最高速率只有100M,所以运行example的code并没能体现出多机的价值,性能还不及单机单卡。
Troubleshooting
再多机配置的过程中发现许多问题,因为时间久远,记录下比较深刻的一些。
1. 数据传输验证
之前说到了,多机训练最关键的是在多机之间的通信。如果master与slave之间的数据传输出了问题,铁定是不会成功的。这个时候需要我们对传输的有效性进行一步步的验证。
1.1 ssh免密验证
验证非常简单,在master(w2)中使用ssh w1看是否能够直接登录,可以的话就说明ssh的免密配置成功,否则重新配置一遍。
1.2 scp远程传输测试
虽然能够免密成功,但可能会出现传输不了文件的情况。这个时候可以在master机器和slave机器之间使用scp命令测试是否能够在多台机器之间完成数据传输。笔者就在实验中发现scp传输失败,网上尝试了贼多方法,最终发现是需要修改MTU的值,默认是1500。ppp0是我拨号上网的接口名。
1 | sudo ip link set ppp0 mtu 1492 |
参考
Training Neural Nets on Larger Batches